根据 linux 内核中的kprobe.txt,当我阅读 linux 内核的源代码以满足工作需要时,我对 kprobe 的工作方式有一个疑惑:
1.1 Kprobe 是如何工作的?
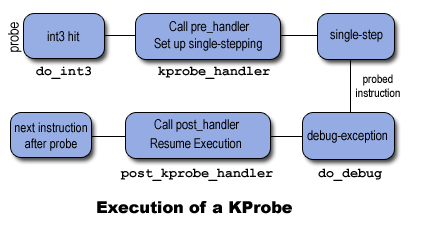
当 kprobe 被注册时,Kprobes 会复制被探测的指令,并用断点指令(例如,i386 和 x86_64 上的 int3)替换被探测指令的第一个字节。
当 CPU 遇到断点指令时,会发生陷阱,保存 CPU 的寄存器,并通过 notifier_call_chain 机制将控制权传递给 Kprobes。Kprobes 执行与 kprobe 关联的“pre_handler”,向处理程序传递 kprobe 结构的地址和保存的寄存器。
接下来,Kprobes 单步执行其探测指令的副本。(单步执行实际指令会更简单,但 Kprobes 将不得不暂时删除断点指令。这将打开一个小的时间窗口,此时另一个 CPU 可以直接越过探测点。)
在指令单步执行后,Kprobes 执行与 kprobe 相关联的“post_handler”(如果有)。然后继续执行探测点之后的指令。
给出了三个步骤,但为什么需要singleandpost_handler过程?我的意思是在用断点指令替换原始指令后,处理器被困在执行 中pre-handler,为什么不直接将原始指令复制回 pc 减 1pre-handler并恢复中断上下文?
请给个提示。
为了清楚起见,请参阅此处的图表。
{kind=link}